La validazione dei modelli è stata un’area di estremo interesse per molte istituzioni finanziarie che si affidano ai modelli statistici per l’underwriting, il pricing, il reserving e il Capital Management. Tradizionalmente, per creare modelli che permettessero di fare previsioni sono state utilizzate tecniche relativamente trasparenti e consolidate all’interno del mondo statistico quali la regressione lineare (LM), i modelli lineari generalizzati (GLMs) e altri metodi statistici. Tuttavia, i recenti sviluppi tecnologici e dei software open source hanno aumentato la potenza computazionale, favorendo la fruibilità di algoritmi di elaborazione dati più efficaci, generando un aumento della richiesta di soluzioni predittive più avanzate e sofisticate. A tale richiesta, il mercato ha risposto con gli algoritmi di Machine Learning.
Limitate sino a qualche anno fa al solo mondo accademico, queste tecniche di modelling predittivo sono in grado di effettuare previsioni più accurate rispetto ai metodi di modelling più tradizionali. Tuttavia, l’aumento del potere predittivo porta con sé maggiori rischi legati appunto alla modellazione. I processi che consentono a queste nuove tecniche di ottenere buoni risultati fanno sì che i processi stessi siano complessi e meno trasparenti di quelli tradizionali. Se vi è scarsa trasparenza nel processo di modelling è facile per un utente non esperto usare impropriamente le tecniche di Machine Learning e generare risultati di tipo “balck box”, a causa di una inadeguata comprensione delle relazioni sottostanti e rendendo ancora più cruciale la validazione del modello.
Breve overview delle tecniche di Machine Learning
Le tecniche di Machine Learning appartengono ad una famiglia di algoritmi che racchiudono insieme la statistica applicata e le scienze informatiche. A differenza dei metodi tradizionali di regressione, le Machine Learning sono tecniche non parametriche, ovvero non vincolate da una forma funzionale e libere da qualsiasi tipo di assunzione a priori di distribuzione statistica. Nelle tecniche parametriche, di cui la regressione lineare è un esempio, un aumento di una variabile indipendente (ad esempio la variabile che spiega un risultato quale la variazione dei prezzi delle abitazioni) deve determinare esclusivamente un aumento o una diminuzione della variabile dipendente (ad esempio, il risultato che si sta stimando, come il numero delle persone con mutuo che sono in difficoltà o che falliscono). Nelle tecniche di Machine Learning, l’effetto di una variabile indipendente su quella dipendente può differire in base ai livelli e alle interazioni con altre variabili. La capacità di catturare queste interazioni attraverso diversi valori delle variabili consente a queste tecniche di andare oltre i tradizionali modelli parametrici.
Anche se sono disponibili numerosi algoritmi di Machine Learning, gli stessi possono essere suddivisi in due diverse macro categorie, supervised e unsupervised, che differiscono tra loro nei criteri utilizzati per classificare i dati o nel fornire le predizioni.
Nella prima categoria di metodologie, i supervised, l’algoritmo suddivide i dati in base a una variabile target definibile a priori, che può essere continua o discreta, a seconda dell’algoritmo utilizzato. Per dividere e classificare i dati, l’algoritmo li suddivide in modo iterativo in base a diverse variabili per ridurre al minimo una funzione di costo. Esistono molte funzioni di costo diverse, ma in generale tutte misurano la differenza tra i valori previsti e quelli osservati. Grazie alla loro capacità di generare previsioni accurate, queste tecniche di apprendimento trovano numerose applicazioni nella gestione dei rischi. Alberi di Classificazione e Regressione, Random Forest sono tutte tecniche di apprendimento supervised.
Nella seconda categoria, gli algoritmi unsupervised, non esiste alcuna variabile target definibile a priori in base alla quale i dati sono suddivisi. Al contrario, l’algoritmo raggruppa le osservazioni in base a quanto esse sono simili tra loro rispetto a determinate dimensioni. Queste tecniche vengono spesso utilizzate in campagne di marketing per personalizzare manovre ed interventi pubblicitari per gruppi di consumatori simili. Tecniche di clustering quali la K-means e modelli di Markov sono esempi di tecniche di apprendimento unsupervised.
Potenziali criticità di Machine Learning
Se da un lato questi algoritmi di apprendimento automatico hanno le potenzialità per migliorare i processi aziendali, affinare le previsioni dei risultati e contenere i costi, dall’altro lato presentano potenziali criticità da tenere in considerazione nel processo di validazione del modello previsionale. Di seguito sono riportate tre potenziali criticità comunemente associate a queste tecniche di apprendimento.
Overfitting (eccessivo adattamento)
Le tecniche di Machine Learning e gli algoritmi di classificazione sono più sensibili al fenomeno dell’overfitting rispetto ai più tradizionali modelli di previsione. L’overfitting si verifica quando un modello basa le sue previsioni su correlazioni spurie all’interno di un campione di dati anziché su relazioni autentiche esistenti all’interno della popolazione nel suo complesso. Mentre i modelli lineari ed i GLMs possono generare livelli contenuti di overfitting, gli algoritmi di Machine Learning sono ancora più sensibili a questo tipo di criticità, principalmente a causa della mancanza di vincoli parametrici. In assenza di una forma funzionale, questi algoritmi possono utilizzare ogni relazione, lineare e non, tra le variabili nei dati del campione di training, per eseguire raggruppamenti e/o fare previsioni. Il maggior rischio è che ogni singolo campione, su cui viene costruito il modello, abbia le proprie peculiarità che non riflettano puntualmente la vera popolazione, riducendo il potere di replicabilità del fenomeno osservato nella totalità dei dati. Gli alberi di Classificazione e di Regressione sono particolarmente sensibili a questa tipologia di criticità, in quanto possono suddividere i dati fino a raggiungere la classificazione perfetta o quasi perfetta, generando così alcune partizioni fuorvianti.
Se un modello caratterizzato da overfitting viene applicato a nuovi dati appartenenti alla stessa popolazione, può, potenzialmente, produrre previsioni poco accurate. Vista l’importanza che molte aziende attribuiscono nei processi decisionali alle analisi predittive, questa mancata accuratezza può avere effetti molto distorsivi.
Riduzione della trasparenza
Le tecniche di Machine Learning riducono, inoltre, la trasparenza del processo interpretativo del modello previsionale. Con le tecniche di regressione più tradizionali, è più intuitivo vedere come interagiscono le variabili all’interno del modello; infatti per valutare la significatività e la direzione di un effetto, è sufficiente esaminare un singolo coefficiente. Se quest’ultimo è positivo, ciò implica una relazione positiva tra la variabile indipendente di interesse e la variabile dipendente, e viceversa. La maggior parte delle tecniche di apprendimento automatico non produce tuttavia risultati così facilmente interpretabili. Alcuni algoritmi, come gli alberi di Classificazione e Regressione semplici, presentano grafici abbastanza comprensibili, ma altri, quali il Gradient Boosting, le Random Forest e le Reti Neurali, funzionano come delle specie di “scatole nere” diminuendo la trasparenza e l’interpretabilità della metodologia sottostante. Sebbene un utente possa inserire i dati e le specificità del modello e pur essendo possibile esaminare i vari steps intermedi generati dall’algoritmo per capire come è in grado di generare le previsioni, spesso è necessario ed opportuno possedere una conoscenza molto approfondita e consolidata di queste tecniche per poter valutare con trasparenza e giudizio critico l’intero processo.
Se non si è in grado di capire in che modo il modello genera i risultati, gli utenti potrebbero ignorare la presenza di distorsioni latenti ed errori, provocati da inadeguati settaggi ad-hoc del modello, i quali comporterebbero un risultato addirittura controproducente perché andrebbero a ridurre le possibilità di aumentare il potere predittivo. Nelle tecniche di regressione tradizionali, uno sguardo alla direzione e alla significatività del singolo coefficiente, agli standard error ed all’adattamento complessivo dei modelli ai dati, consente agli utenti di avere un’idea, per quanto approssimativa, del corretto potere predittivo dei modelli utilizzati. Se la maggioranza dei coefficienti delle variabili risultano non significativi, la bontà di adattamento del modello è inaccurata, o se le variabili non hanno il potere esplicativo previsto, l’utente sa che il modello potrebbe contenere un errore o un settaggio non ottimale. Il modello potrebbe essere stato adattato su dati non adeguati, scarsamente specificati o utilizzati in un contesto non corretto. Con le tecniche di Machine Learning, tuttavia, la mancanza di trasparenza nelle previsioni rende più difficoltosa l’individuazione di questi tipi di criticità.
Risultati che si basano su dati campionari non adeguati
La qualità dei risultati ottenuti da un modello è direttamente proporzionale a quella dei dati su cui viene costruito. Le tecniche di Machine Learning non fanno eccezione a questa regola. Come detto precedentemente, a causa della scarsa trasparenza di questi algoritmi è facile che agli utenti possano sfuggire potenziali criticità presenti nel processo di modelling, ad esempio che previsioni poco accurate siano dovute da dati campionari non adeguati. Nonostante la gran quantità dei dati disponibili grazie ai progressi conseguiti in campo tecnologico, si devono adottare misure adeguate per assicurarsi che tutti i campioni utilizzati per il modelling siano rappresentativi della popolazione nel suo complesso. Tecniche di campionamento incomplete, o poco idonee al tipo di proiezione che si intende produrre, possono fornire dati non rappresentativi della popolazione nella sua interezza. Oltre alle tecniche di campionamento imperfette o non idonee alla finalità dell’analisi, anche l’utilizzo di dati troppo poco recenti può comportare dei rischi nel processo di modelling. Se un campione utilizzato nel processo di modellazione non rappresenta più il processo sottostante che lo genera, il modello produrrà risultati distorti e non in linea con il trend oggetti di analisi.
Tecniche di validazione dei modelli
Una validazione indipendente del modello condotta da esperti professionisti può ridurre i rischi associati alle nuove tecniche di modellazione. Nonostante la novità delle tecniche di Machine Learning, esistono diversi metodi per mitigare l’effetto dell’overfitting e di altre problematicità nel settaggio del modello previsionale. Il requisito più importante per la validazione del modello è che il team che ne valuti la bontà di adattamento comprenda a pieno la corretta operatività dell’algoritmo. Se nella fase di validazione non si conosce la teoria e le ipotesi sottostanti alla base del modello o si ha un’esperienza limitata nel modelling di queste tecniche, è probabile che non si sia in grado di eseguirne una valutazione efficace. Al fine di eseguire una validazione coerente e consistente del processo di modellazione è utile prendere in esame le procedure riportate di seguito.
Analisi dei risultati
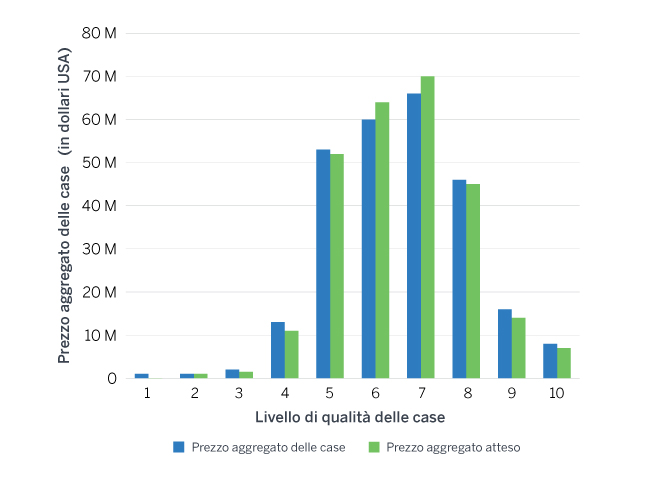
Con analisi dei risultati si intende la comparazione dei risultati stimati rispetto ai dati osservati. Per queste tecniche avanzate di previsione, l’analisi dei risultati rappresenta, pur nella sua semplicità, un approccio molto utile per comprendere e valutare le interazioni e le potenziali criticità del modello implementato. Un modo per comprendere il potere predittivo del modello è quello di rappresentare in un diagramma i valori della variabile indipendente in funzione sia del risultato osservato che di quello stimato, insieme al numero di osservazioni. Ciò consente all’utente di osservare la relazione univariata all’interno del modello e valutare il livello di overfitting prodotto. Per valutare le possibili interazioni, possono essere creati anche diagrammi incrociati valutando i risultati in due dimensioni anziché in una. Oltre le due dimensioni diventa difficile valutare i risultati, ma osservando le interazioni univoche si acquisisce una prima comprensione del comportamento del modello rispetto alle singole variabili indipendenti utilizzate.
Figura 1: Prezzo aggregato effettivo delle case rispetto al prezzo atteso (in base alla qualità delle case)
Cross Validation
La Cross Validation è una tecnica frequentemente utilizzata per assicurarsi che un modello non produca un eccessivo livello di overfitting rispetto ai dati campionari sui quali è sviluppato. È stata utilizzata in passato per contribuire ad assicurare l’integrità di altri metodi statistici e con la crescente popolarità delle tecniche di Machine Learning, ha visto incrementarsi il suo utilizzo. Con tale tecnica, un modello viene costruito ed adattato utilizzando solo una parte del campione di dati a disposizione, utilizzando la restante porzione per valutarne l’effettivo potere predittivo. In condizioni ideali, il modello funzionerà ugualmente bene su entrambe le porzioni di dati. In caso contrario, è probabile la presenza di un livello di overfitting non trascurabile. I dati campionari vengono solitamente suddivisi in proporzione 80-20, in cui l’80% viene utilizzato per adattare o “addestrare” il modello (training data set) e il restante 20% (validation data set) viene impiegato per valutarne la capacità predittiva. Esistono anche approcci più rigorosi alla Cross Validation, tra cui la k-fold Validation, che prevede che il processo sopra esposto venga ripetuto k volte con diverse suddivisioni dei dati campionari.
Figura 2: K-fold validation
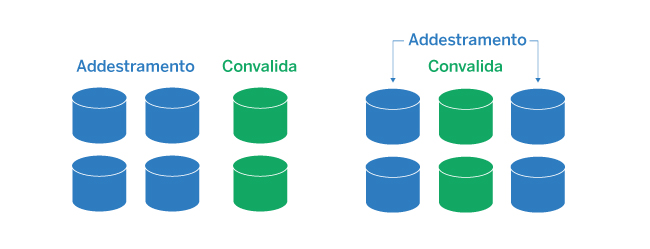
Per la valutazione del modello, la Cross Validation può essere utilizzata per confrontare la stabilità del modello previsionale finale e per valutare l’accuratezza delle previsioni per le stesse esposizioni basate sulla modifica del training data set utilizzato. In pratica, si può addestrare ed allenare il modello con differenti tipi di dati campionari, e valutare sequenzialmente le previsioni prodotte al fine di determinare se il modello è eccessivamente sensibile ai dati utilizzati per la fase di training.
Grafico dell’importanza delle variabili
Se da un lato la Cross Validation può aiutare a prevenire e a mitigare il fenomeno dell’overfitting, dall’altro lato non mette al riparo l’utente da eventuali distorsioni prodotte da dati non adeguati. In particolare, se i dati sono scarsamente campionati e non rappresentativi della popolazione sottostante, eventuali inadeguatezze verranno rilevate e risolte durante il processo esplorativo dei dati. Ma data la difficoltà nella definizione e nella rilevazione di dati non adeguati, talvolta risulta difficile individuare questo tipo di problematicità. Quando ciò accade, occorre mettere in atto altre misure per esaminare il modo in cui un modello utilizza i dati per generare i risultati. Come detto in precedenza, la complessità della maggior parte degli algoritmi di Machine Learning rende difficile questo compito. Tuttavia, molte implementazioni di questi algoritmi di apprendimento automatico nei software open-source possono produrre grafici utili ad una migliore calibrazione del modello; un esempio è fornito dai grafici che mostrano quali sono le variabili più importanti e con maggiore potere predittivo. L’esame di uno di questi grafici sotto riportati, può dare indicazioni agli utenti di eventuali criticità nel modello implementato. Se le variabili tradizionalmente più importanti stanno contribuendo poco nel modello, ciò potrebbe indicare che una inadeguata specificazione o eventuali criticità sull’accuratezza dei dati utilizzati.
Figura 3: Importanza della variabili, algoritmo Random Forest
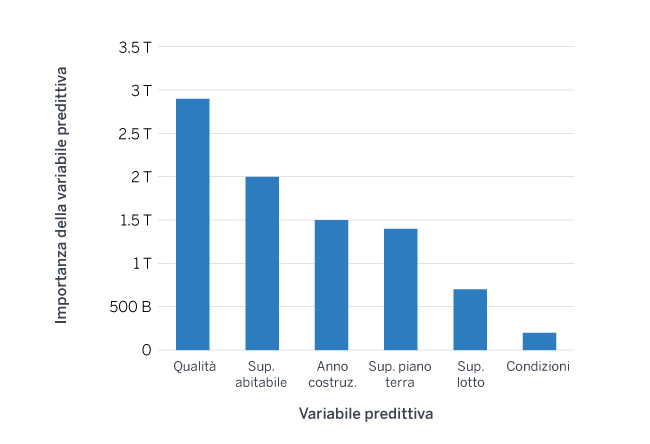
Esempio di grafico rappresentate l’importanza delle variabili predittive in un modello Random Forest
In generale, i grafici rappresentanti l’importanza delle variabili predittive vengono generati nel processo di valutazione del modello a tal fine di determinare se le variabili più influenti sono intuitivamente ragionevoli e/o se sono coerenti con i risultati di modelli realizzati con un approccio diverso (ad esempio, regressione).
Conclusione
Con il progredire della tecnologia, le tecniche di Machine Learning sono destinate a trovare sempre più spazio nel mondo tecnico-attuariale. Queste tecniche hanno il potenziale per contribuire a migliorare i processi aziendali, ottimizzare il processo di gestione dei rischi e a favorire la ricerca. Ma l’utilizzo di queste tecniche non è privo di potenziali criticità che possono minare l’effettiva adeguatezza dell’intero modello previsionale. I rischi sopracitati sottolineano l’importanza di una validazione indipendente ed esterna del modello. Una corretta verifica e validazione del modello consente agli utenti di essere più confidenti sull’affidabilità dei risultati prodotti da queste tecniche e meno preoccupati per i rischi potenziali.